
Learn from your fellow PHP developers with our PHP blogs, or help share the knowledge you've gained by writing your own.

umask(0);
$pid = pcntl_fork();
if ($pid < 0) {
print('fork failed');
exit 1;
}
if ($pid > 0) { echo "daemon process started
";
exit;
}
$sid = posix_setsid();
if ($sid < 0) {
exit 2;
}
chdir('/');
file_put_contents($pidFilename, getmypid() );
run_process();ob_start();
var_dump($some_object);
$content = ob_get_clean();
fwrite($fd_log, $content); ini_set('error_log', $logDir.'/error.log');
fclose(STDIN);
fclose(STDOUT);
fclose(STDERR);
$STDIN = fopen('/dev/null', 'r');
$STDOUT = fopen($logDir.'/application.log', 'ab');
$STDERR = fopen($logDir.'/application.error.log', 'ab');
function sig_handler($signo)
{
global $fd_log;
switch ($signo) {
case SIGTERM:
fclose($fd_log); unlink($pidfile); exit;
break;
case SIGHUP:
init_data(); break;
default:
}
}
pcntl_signal(SIGTERM, "sig_handler");
pcntl_signal(SIGHUP, "sig_handler");
$base = event_base_new();
$event = event_new();
$errno = 0;
$errstr = '';
$socket = stream_socket_server("tcp://$IP:$port", $errno, $errstr);
stream_set_blocking($socket, 0);
event_set($event, $socket, EV_READ | EV_PERSIST, 'onAccept', $base);
function onRead($buffer, $id)
{
while($read = event_buffer_read($buffer, 256)) {
var_dump($read);
}
}
function onError($buffer, $error, $id)
{
global $id, $buffers, $ctx_connections;
event_buffer_disable($buffers[$id], EV_READ | EV_WRITE);
event_buffer_free($buffers[$id]);
fclose($ctx_connections[$id]);
unset($buffers[$id], $ctx_connections[$id]);
}
$event2 = event_new();
$tmpfile = tmpfile();
event_set($event2, $tmpfile, 0, 'onTimer', $interval);
$res = event_base_set($event2, $base);
event_add($event2, 1000000 * $interval);
function onTimer($tmpfile, $flag, $interval)
{
$global $base, $event2;
if ($event2) {
event_delete($event2);
event_free($event2);
}
call_user_function(‘process_data’,$args);
$event2 = event_new();
event_set($event2, $tmpfile, 0, 'onTimer', $interval);
$res = event_base_set($event2, $base);
event_add($event2, 1000000 * $interval);
}
event_delete($event);
event_free($event);
event_base_free($base);
event_base_set($event, $base);
event_add($event);
function onAccept($socket, $flag, $base) {
global $id, $buffers, $ctx_connections;
$id++;
$connection = stream_socket_accept($socket);
stream_set_blocking($connection, 0);
$buffer = event_buffer_new($connection, 'onRead', NULL, 'onError', $id);
event_buffer_base_set($buffer, $base);
event_buffer_timeout_set($buffer, 30, 30);
event_buffer_watermark_set($buffer, EV_READ, 0, 0xffffff); event_buffer_priority_set($buffer, 10); event_buffer_enable($buffer, EV_READ | EV_PERSIST); $ctx_connections[$id] = $connection;
$buffers[$id] = $buffer;
}
#! /bin/sh
#
$appdir = /usr/share/myapp/app.php
$parms = --master –proc=8 --daemon
export $appdir
export $parms
if [ ! -x appdir ]; then
exit 1
fi
if [ -x /etc/rc.d/init.d/functions ]; then
. /etc/rc.d/init.d/functions
fi
RETVAL=0
start () {
echo "Starting app"
daemon /usr/bin/php $appdir $parms
RETVAL=$?
[ $RETVAL -eq 0 ] && touch /var/lock/subsys/mydaemon
echo
return $RETVAL
}
stop () {
echo -n "Stopping $prog: "
killproc /usr/bin/fetchmail
RETVAL=$?
[ $RETVAL -eq 0 ] && rm -f /var/lock/subsys/mydaemon
echo
return $RETVAL
}
case in
start)
start
;;
stop)
stop
;;
restart)
stop
start
;;
status)
status /usr/bin/mydaemon
;;
*)
echo "Usage: {start|stop|restart|status}"
;;
RETVAL=$?
exit $RETVAL
#php app.phar
myDaemon version 0.1 Debug
usage:
--daemon – run as daemon
--debug – run in debug mode
--settings – print settings
--nofork – not run child processes
--check – check dependency modules
--master – run as master
--proc=[8] – run child processes

We highly recommend that you follow these tutorials on a localhost testing server like Uniserver. Read through Part 1 here to look at our recommendations. These tutorials follow a phased approach and it is highly recommended that you do not make snippets of code live prior to completing this tutorial series.
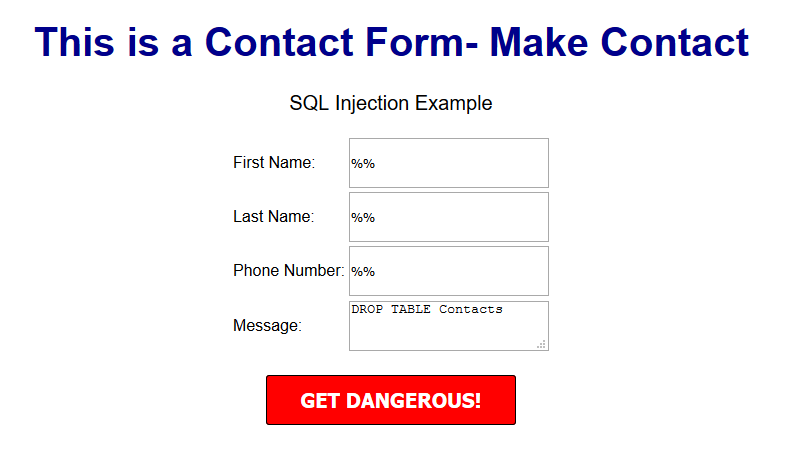
$sql = "INSERT INTO content(title,content,author)VALUES ('".$_POST["title"]."', '".$_POST["content"]."', '".$_POST["author"]."')";
$title = $letsconnect -> real_escape_string($_POST['title']);
$content = $letsconnect -> real_escape_string($_POST['content']);
$author = $letsconnect -> real_escape_string($_POST['author']);
$letsconnect? This was used because of our db connection defined in conn.php.$sql = "INSERT INTO content (title,content,author) VALUES ('".$title."', '".$content."', '".$author."')";
$sql.
$users = [new User(), new User()];
public function getUsers(): array
{
return $userArray;
}
public function setUsersToActiveState()
{
$users = $this->getUsers();
foreach ($users as $user) {
if(!$user->getActiveStatus()) {
$user->setActiveStatus(true);
}
}
}
class UsersCollection implements \IteratorAggregate
{
private $users = [];
public function getIterator() : UserIterator
{
return new UserIterator($this);
}
public function getUser($position)
{
if (isset($this->users[$position])) {
return $this->users[$position];
}
return null;
}
public function count() : int
{
return count($this->users);
}
public function addUser(User $users)
{
$this->users[] = $users;
}
}
class UserIterator implements \Iterator
{
private $position = 0;
private $userCollection;
public function __construct(UsersCollection $userCollection)
{
$this->userCollection = $userCollection;
}
public function current() : User
{
return $this->userCollection->getUser($this->position);
}
public function next()
{
$this->position++;
}
public function key() : int
{
return $this->position;
}
public function valid() : bool
{
return !is_null($this->userCollection->getUser($this->position));
}
public function rewind()
{
$this->position = 0;
}
}
class UsersCollectionTest extends TestCase
{
public function testUsersCollectionShouldReturnNullForNotExistingUserPosition()
{
$usersCollection = new UsersCollection();
$this->assertEquals(null, $usersCollection->getUser(1));
}
public function testEmptyUsersCollection()
{
$usersCollection = new UsersCollection();
$this->assertEquals(new UserIterator($usersCollection), $usersCollection->getIterator());
$this->assertEquals(0, $usersCollection->count());
}
public function testUsersCollectionWithUserElements()
{
$usersCollection = new UsersCollection();
$usersCollection->addUser($this->getUserMock());
$usersCollection->addUser($this->getUserMock());
$this->assertEquals(new UserIterator($usersCollection), $usersCollection->getIterator());
$this->assertEquals($this->getUserMock(), $usersCollection->getUser(1));
$this->assertEquals(2, $usersCollection->count());
}
private function getUserMock()
{
}
}
class UserIteratorTest extends MockClass
{
public function testCurrent()
{
$iterator = $this->getIterator();
$current = $iterator->current();
$this->assertEquals($this->getUserMock(), $current);
}
public function testNext()
{
$iterator = $this->getIterator();
$iterator->next();
$this->assertEquals(1, $iterator->key());
}
public function testKey()
{
$iterator = $this->getIterator();
$iterator->next();
$iterator->next();
$this->assertEquals(2, $iterator->key());
}
public function testValidIfItemInvalid()
{
$iterator = $this->getIterator();
$iterator->next();
$iterator->next();
$iterator->next();
$this->assertEquals(false, $iterator->valid());
}
public function testValidIfItemIsValid()
{
$iterator = $this->getIterator();
$iterator->next();
$this->assertEquals(true, $iterator->valid());
}
public function testRewind()
{
$iterator = $this->getIterator();
$iterator->rewind();
$this->assertEquals(0, $iterator->key());
}
private function getIterator() : UserIterator
{
return new UserIterator($this->getCollection());
}
private function getCollection() : UsersCollection
{
$userItems[] = $this->getUserMock();
$userItems[] = $this->getUserMock();
$usersCollection = new UsersCollection();
foreach ($userItems as $user) {
$usersCollection->addUser($user);
}
return $usersCollection;
}
private function getUserMock()
{
}
}
public function getUsers(): UsersCollection
{
$userCollection = new UsersCollection();
foreach ($whatIGetFromDatabase as $user) {
$userCollection->addUser($user);
}
return $userCollection;
}
public fucntion setUsersToActiveState()
{
$users = $this->getUsers();
foreach ($users as $user) {
if(!$user->getActiveStatus()) {
$user->setActiveStatus(true);
}
}
}
public function addUser(User $users)
{
if ($user->getAge() > 18) {
$this->users[] = $users;
}
}
public function addUsers(array $users)
{
foreach($users as $user) {
$this->addUser(User $users);
}
}

$ php -i
phpinfo()
PHP Version => 7.2.10-0ubuntu1
System => Linux awesome 4.18.0-10-generic #11-Ubuntu SMP Thu Oct 11 15:13:55 UTC 2018 x86_64
Build Date => Sep 13 2018 13:38:55
Server API => Command Line Interface
Virtual Directory Support => disabled
...
less command in order to get pagination and search: php -i | less. Type Q to exit the less shell. Some distros might lack less, in that case you may try php -i | more, which doesn't give you search but still has pagination.$ php -m
[PHP Modules]
calendar
Core
ctype
date
dom
ds
exif
...
$ php --re ds
Extension [ <persistent> extension #46 ds version 1.2.6 ] {
- Dependencies {
Dependency [ json (Required) ]
Dependency [ spl (Required) ]
}
- Classes [11] {
Interface [ <internal:ds> interface Ds\Hashable ] {
- Constants [0] {
}
- Static properties [0] {
}
...
$ php --rc Ds\Vector
Class [ <internal:ds> <iterateable> final class Ds\Vector implements Ds\Sequence, Traversable, Countable, JsonSerializable, Ds\Collection ] {
- Constants [1] {
Constant [ public integer MIN_CAPACITY ] { 8 }
}
- Static properties [0] {
}
...
$ php --rf fopen
Function [ <internal:standard> function fopen ] {
- Parameters [4] {
Parameter #0 [ <required> $filename ]
Parameter #1 [ <required> $mode ]
Parameter #2 [ <optional> $use_include_path ]
Parameter #3 [ <optional> $context ]
}
}
-a switch might be what you're looking for:$ php -a
Interactive mode enabled
php > var_dump(join(", ", [1, 2, 3]));
php shell code:1:
string(7) "1, 2, 3"
php >
readline support (most distros have that anyway).$ php -l test.php
PHP Parse error: syntax error, unexpected 'array_shift' (T_STRING) in test.php on line 4
Errors parsing test.php
$ cd /my_application/document_root
$ php -S localhost:8000

Technology is constantly changing the way we interact, research, and react. One such way artificial intelligence is impacting our daily lives, and we may not even realize it is in weather forecasting.
 g10dra 116,156
g10dra 116,156  mike 79,533
mike 79,533  crocodile2u 78,043
crocodile2u 78,043  harikrishnanr 62,303
harikrishnanr 62,303  calevans 37,823
calevans 37,823  MindNovae 28,778
MindNovae 28,778  dmamontov 19,376
dmamontov 19,376  tanja 16,717
tanja 16,717  damnjan 13,150
damnjan 13,150  ahmedkhan
ahmedkhan SPONSORS

SPONSORS


